ULIX: Literate Unix
ULIX: Literate Unix
A diary documenting the implementation of ULIX-i386
|
Welcome to the ULIX blog.
Ulix (Literate Unix) is a Unix-like operating system developed at
University of Erlangen-Nürnberg.
I use D. E. Knuth's concept of
Literate Programming
for the implementation and documentation. The goal was a fully working system which can be
used in operating system courses to show students how OS concepts (such as paging and scheduling)
can be implemented. Literate programs are very accessible because they can be read like a book;
the order of presentation is not enforced by program logic or compiler restrictions, but instead
is guided by the implementer's creative process.
Ulix is written in C and assembler for the Intel architecture. The literate programming
part is handled by noweb.
On this page I document my progress with the implementation.
|

|
Navigation:
2015 |
2014 |
2013 |
2012 |
2011
|
| v0.13: First public release (04.11.2015) | |
Yesterday, I put the first public release of Ulix online. You can get it
from the ulixos.org website.
Both the source code (hosted on GitHub) as well as the Ulix book are
available from that site.
Also, in September my PhD thesis (which also contains the Ulix book as a
huge appendix) was published. It is available on the university's
webserver
(PDF, 1054 pages, 11.5 MByte).
[ Path: | persistent link ]
| |
| v0.12: Ulix code and book finished (02.09.2014) | |
 One week ago I finished work on the first edition of the Ulix book.
It will be published once my PhD dissertation has been accepted and
defended, but I can already say that the book has almost 700 pages
with lots of figures and tables. Ulix seems to be stable enough
for playing a bit with it.
One week ago I finished work on the first edition of the Ulix book.
It will be published once my PhD dissertation has been accepted and
defended, but I can already say that the book has almost 700 pages
with lots of figures and tables. Ulix seems to be stable enough
for playing a bit with it.
The latest additions to the code were pthread-style threads
(implemented in the kernel, but with a user mode interface)
and pthread mutexes.
A printed version of the book sits beside my other operating
systems books (see picture), and I like it a lot :)
[ Path: | persistent link ] | |
| v0.11: Filesystem Code complete (23.04.2014) | |
The latest Ulix version's filesystem code is feature-complete.
All Minix2 functions work fully (including support for single
and double indirection blocks and directories with up to 7x16
entries),
there's a new virtual /dev filesystem which allows access to
the two floppies, two harddisks and RAM (/dev/kmem), the buffer
cache is now used for caching writeblock() calls as well.
There's also the beginning of a kernel mode thread package
with some of the pthread_ and pthread_mutex_ functions.
[ Path: | persistent link ] | |
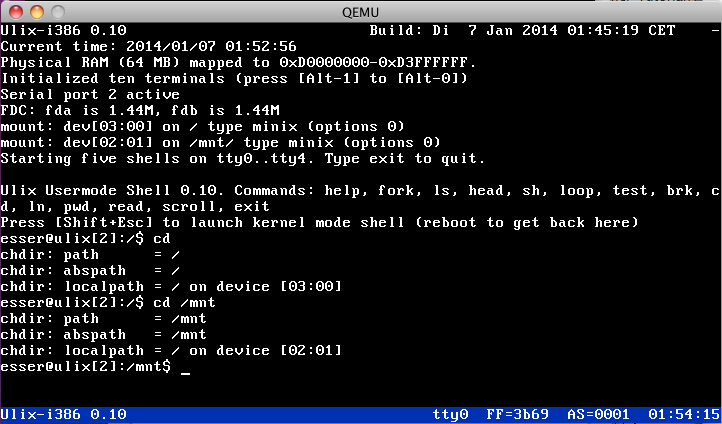
| v0.10: VFS, switch to kernel shell (and back) (07.01.2014) | |
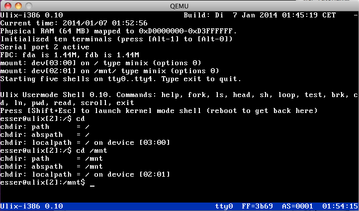 The Virtual Filesystem (VFS) mentioned in the 0.09 news is complete now which
means: we can 'cd' to directories on mounted media, read, write, and delete
files and show directory contents.
The Virtual Filesystem (VFS) mentioned in the 0.09 news is complete now which
means: we can 'cd' to directories on mounted media, read, write, and delete
files and show directory contents.
Entering the kernel mode shell via Shift+Esc (which was possible before) is no
longer a one-way ticket, typing exit brings us back to the user mode program.
Also, the "ULIX lectures" (the OS development course at TH Nuremberg) is about
to end soon, with most of the ULIX code presented during the lectures (or worked
on/rebuilt in the tutorial sessions).
What's left for ULIX? Signaling, Page Replacement, User mode synchronization.
[ Path: | persistent link ]
| |
| v0.09: IDE Disk, exec, vi (02.11.2013) | |
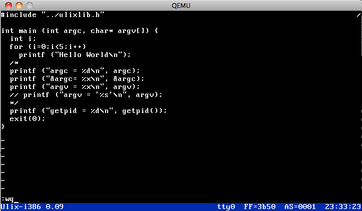 For a few months, Ulix has been able to use IDE hard disks. There's now also a
virtual filesystem layer which lets the system mount hard disks and floppy disks
to sub directories (but that's not complete yet; so far only one mounted device).
For a few months, Ulix has been able to use IDE hard disks. There's now also a
virtual filesystem layer which lets the system mount hard disks and floppy disks
to sub directories (but that's not complete yet; so far only one mounted device).
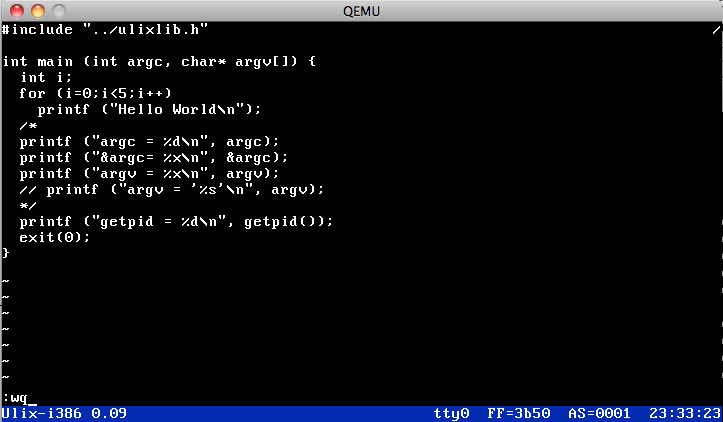
I've also written execve() which loads ELF binaries. Many tools which were shell-built-ins
have now become "proper" external commands, residing in a /bin/ folder. The first real
application is an ultra-simple vi clone: so far the editor can open and save files,
switch between command and edit mode and actually insert/delete text. The only working
commands are dd (delete line), x (delete character), wq (write and quit), and
q! (quit without saving). The picture shows vi editing a C file.
The next release should see a completion of the virtual filesystem (with mount / umount
commands) and the signaling code mentioned earlier.
[ Path: | persistent link ]
| |
| Buffer Cache (19.07.2013) | |
After noticing that disk access is pretty slow (because many blocks
are being read over and over again) I introduced a simple buffer
cache which can store 256 disk blocks im RAM. This has really sped
up the access times; reading and writing feel normal now.
Currently only read operations are buffered. Maybe later I'll also
buffer write operations and add a sync system call; but reading
occurs much more often than writing.
[ Path: | persistent link ] | |
| Filesystem: Directories, link, unlink (15.07.2013) | |
The Minix code is almost complete: Ulix can now access sub-directories and
files inside those. Relative paths are converted into absolute paths, and
the new functions link() and unlink() are finished. This can all be tested
in user mode, the shell has built-in commands cd, touch, cp, ln, rm.
All filesystem actions have been tested (with fsck.minix), they all leave
the filesystem valid.
What's missing is little things (mkdir, rmdir, symlink; I'll add those in
the next days) and double
indirection which I won't implement, it is only needed for files larger
than 263 KByte, and those are not likely on 1.44 MB floppies.
[ Path: | persistent link ] | |
| Having Fun with Minix (13.07.2013) | |
As I wrote in the last entry, I have implemented (parts of) the
Minix filesystem. I used that one because Linux machines can
create and mount Minix filesystem images. However, I use a Mac
for development, and on those machines it is harder to access
Minix volumes. The MacFUSE-based "minixfs" command can mount a
Minix image, but only read-only, and I have not found software
that can mount them writeable on the Mac.
So I created a small VirtualBox VM with Debian inside, shared
the Mac's filesystem with the VM and created shell scripts
which mount the Minix image and modify it. I had to learn that
this approach doesn't work when the image resides on the
vboxsf shared folder: Files kept disappearing from the image.
The solution was to first physically copy the image into the
VM, mount it, make the changes, unmount it, and copy it back
to the Mac. It works now :)
[ Path: | persistent link ] | |
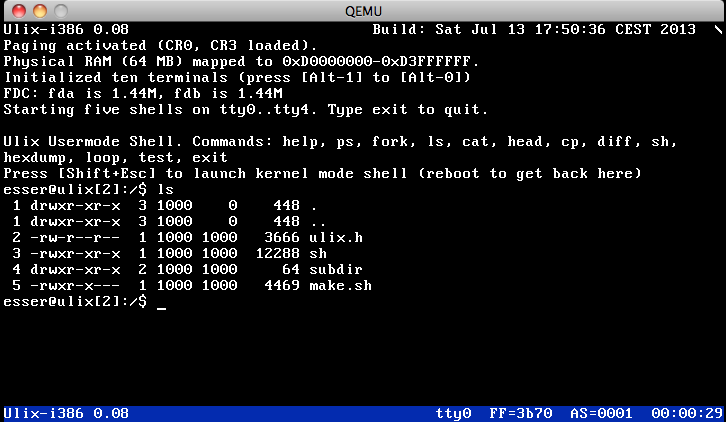
| v0.08: Floppies, Minix Filesystem (13.07.2013) | |
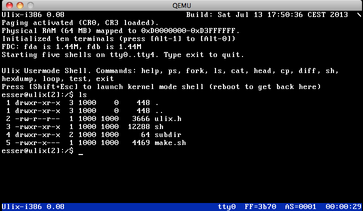 Ulix reads and writes floppy disks (via the FDC controller),
it can handle parallel accesses from several processes (using
a mutex to synchronize things). There's a basic implentation
of the Minix (v2) filesystem: Via standard system calls, processes
can open, read, write, lseek files, and single indirection for
block numbers is possible. No double indirection, and currently
no sub-directories. (The Minix code replaces the older
simplefs filesystem which was a very basic FAT-type system.)
Ulix reads and writes floppy disks (via the FDC controller),
it can handle parallel accesses from several processes (using
a mutex to synchronize things). There's a basic implentation
of the Minix (v2) filesystem: Via standard system calls, processes
can open, read, write, lseek files, and single indirection for
block numbers is possible. No double indirection, and currently
no sub-directories. (The Minix code replaces the older
simplefs filesystem which was a very basic FAT-type system.)
Next: Implementation of signals. There's already a kill()
function and the corresponding system call, but the scheduler
needs modification (for jumping into signal handlers when
signals are found).
[ Path: | persistent link ] | |
| ULIX course at Nuremberg University of Applied Sciences (30.05.2013) | |
Next term (winter 2013/14) I'll offer a course called "Operating
System Development with Literate Programming" at
Nuremberg
University of Applied Sciences (Technische Hochschule
Nürnberg). I'll introduce the literate programming
technique, show ULIX code fragments as examples and let the
students implement further ULIX components as literate programs.
When that course starts, ULIX should be sufficiently developped,
so this gives me a nice deadline for completing the basic code.
[ Path: | persistent link ] | |
| Virtual Consoles, Multiple Shells (30.04.2013) | |
The latest addition to Ulix is that it now supports ten virtual
consoles, each of which can host a shell. That way it is possible
to start tests on one console and watch its behavior (e.g. by
displaying the process list) on another one.
[ Path: | persistent link ]
| |
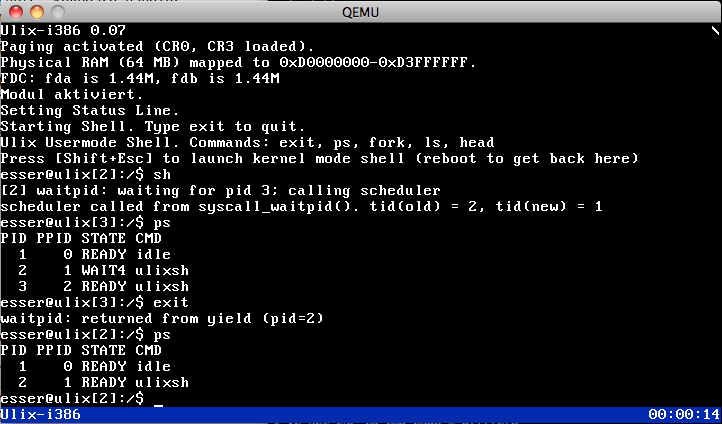
| v0.07: Scheduling, fork(), exit(), and waitpid() are working (05.04.2013) | |
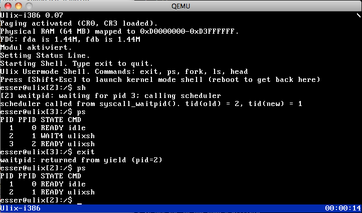 It's taken some time, but I finally got the context switch working,
and so Ulix can now launch new processes and have them all run in
parallel by the (simple round-robin) scheduler. The problem was in the
function which changes the address space (by modifying the CR3 register
which points to the page directory). For some time I thought it should
be sufficient to make that function an inline function, but now I found
that it must not be a function at all (there's still parameter-passing
involved in calling inline functions, and these parameters are lost
when changing the page directory). So now it's not a function call anymore,
instead the scheduler directly switches the page directory,
and everything works.
It's taken some time, but I finally got the context switch working,
and so Ulix can now launch new processes and have them all run in
parallel by the (simple round-robin) scheduler. The problem was in the
function which changes the address space (by modifying the CR3 register
which points to the page directory). For some time I thought it should
be sufficient to make that function an inline function, but now I found
that it must not be a function at all (there's still parameter-passing
involved in calling inline functions, and these parameters are lost
when changing the page directory). So now it's not a function call anymore,
instead the scheduler directly switches the page directory,
and everything works.
The first two Bachelor theses (on Ulix-Filesystem/RAM disk and the ELF binary
loader) are completed, so after I've included the code in Ulix, it will be
able to start programs from disk properly. The third student who is working
on a priority-based scheduler is also about to complete his work in the next
weeks.
[ Path: | persistent link ] | |
| User Mode Shell (25.11.2012) | |
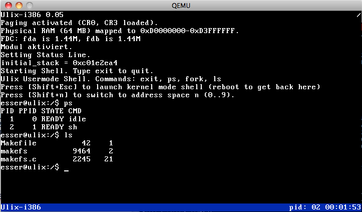 Ulix now boots into a user mode shell -- a real shell process which can fork
new processes. Currently the new shell has only a few (internal) commands;
it can show the process list (ps) and the files on the floppy (ls) and
look into them with the head command. Ah, it also can exit...
Ulix now boots into a user mode shell -- a real shell process which can fork
new processes. Currently the new shell has only a few (internal) commands;
it can show the process list (ps) and the files on the floppy (ls) and
look into them with the head command. Ah, it also can exit...
The rewrite of the task-switching code seems to work a lot better than the
original code which was based on a tutorial that I found on the web. For now,
there are no more problems with the stacks. I've also changed the code for
the system call handlers which now works with the same set of saved registers
as interrupt handlers do; that makes life easier, because there are always
the same data on the stack.
Also, the document which describes Ulix has crossed the 400 pages barrier today.
It will likely grow to something like 600-700 pages before Ulix is finished.
[ Path: | persistent link ] | |
| Redoing the scheduler and init / exec code; floppy access (19.11.2012) | |
Today I started rewriting the code for scheduling and process
initialization (via fork() or load_from_disk()).
The new code uses the fact that all handler functions (which
includes system call handlers) can read the register contents
of the process in user mode (before the interrupt occurred or
the system call was initiated with int 0x80).
Also new in Ulix: I can now access a floppy drive. Reading and
writing sectors works fine in both system mode (during the
OS initialization) and in user mode (through sys calls). For
testing stuff, there's also a rudimentary FAT-like filesystem
(including a makefs command that creates new floppy
images and fills them with files, a bit like genisoimage).
Since so many things depend on one another, there's also a
usermode library (ulixlib) which allows Ulix programs to be
(cross-) compiled with gcc. So it is now possible
to write C programs that open() a file on the
floppy disk and then read() from and write()
to it.
[ Path: | persistent link ] | |
| Executing processes (05.10.2012) | |
Ulix can run processes now. It does not handle several of them nicely yet,
but the news is that programs can be compiled (externally) using a basic
usermode library. So far it can printf() and--sort of--open files and
read/write them.
Compiling requires a linker script which creates a flat binary: So far,
Ulix does not support ELF binaries (but there'll be ELF support early
next year, since a BSc student has just started working on that component).
Such programs can call functions in the usermode library which in turn
make system calls in order to do privileged things (such as writing to
the screen and forking).
After launching a program (which has no way to properly exit() so far),
Shift-Esc jumps back to the shell. The new ps command in that shell shows
what's going on.
[ Path: | persistent link ] | |
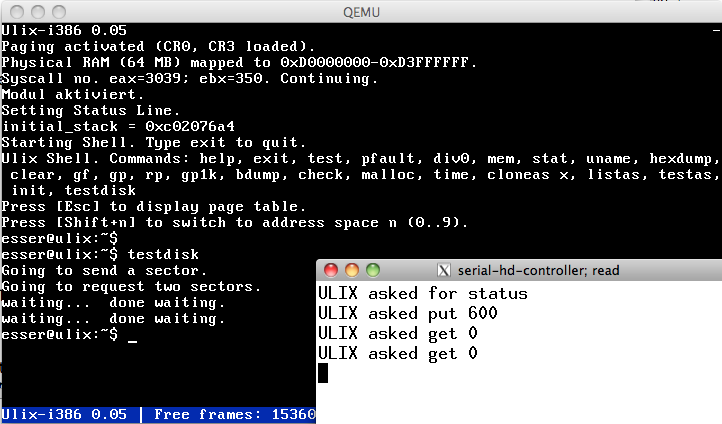
| Ulix has Hard Disk Support (sort of...) (02.10.2012) | |
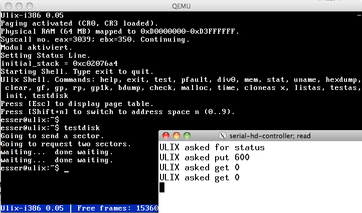 I've been looking at a few implementations of hard disk drivers,
since (obviously) Ulix needs this as well. Since none of the
available solutions is simple enough for inclusion in the
Ulix book, I've decided to cheat a little.
I've been looking at a few implementations of hard disk drivers,
since (obviously) Ulix needs this as well. Since none of the
available solutions is simple enough for inclusion in the
Ulix book, I've decided to cheat a little.
So I present: the serial hard disk. It relies on an external
process that serves as some kind of simple storage server.
Via the serial port, Ulix can request sectors (or send their
content), and the storage process translates this to
reading and writing a disk image.
It already works for non-blocking I/O (i.e. when the kernel
wants to access the disk), when Ulix runs on qemu. (Bochs
support follows soon.) In theory this would also work when
running Ulix on a real machine and connecting the serial
port to another machine running the storage process.
Next up: blocking I/O for processes.
[ Path: | persistent link ] | |
| Moodle... (01.06.2012) | |
When Ulix is finished, there will also be a Moodle course
which can be used as a free introduction to operating
systems. Today I've setup a temporary Moodle site.
[Update 2012/10/20: I've registered a new domain
ulixos.org which will
later host the course.]
[ Path: | persistent link ]
| |
| Processes... (30.05.2012) | |
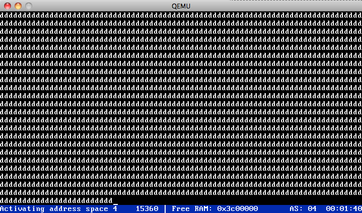 The simple scheduling of several processes works. Each of them uses their
own memory (address spaces), and a simple round robin scheduler cycles
between them. For some reason they cannot access the keyboard input
buffer yet. Next: Fix this input problem; understand why fork only works
when manually moving the child's stack pointer 8 bytes up; create a user
mode library so that processes can be compiled C programs (instead of
inline assembler).
Here's the first running process:
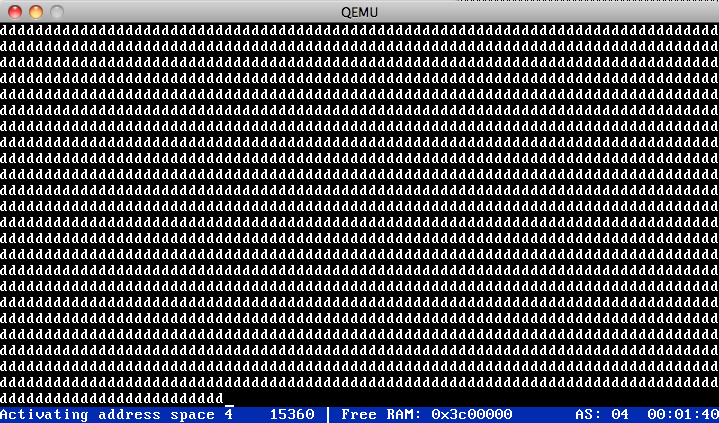
The simple scheduling of several processes works. Each of them uses their
own memory (address spaces), and a simple round robin scheduler cycles
between them. For some reason they cannot access the keyboard input
buffer yet. Next: Fix this input problem; understand why fork only works
when manually moving the child's stack pointer 8 bytes up; create a user
mode library so that processes can be compiled C programs (instead of
inline assembler).
Here's the first running process:
call dofork;
call dofork;
mov ebx, esp; // print ESP
mov eax, 0x1003;
int 0x80;
mov eax, 20; // call getpid()
int 0x80;
mov eax, 0x1000; // store PID in 0x1000
mov [eax], ebx;
loop:
call doshowpid;
jmp loop;
dofork:
mov eax,2; // syscall 2: fork
int 0x80;
ret;
doshowpid:
mov eax,0x1000;
mov ebx,[eax];
add ebx,'a'-1;
mov eax,0x1001; // syscall 0x1001: putchar
int 0x80;
ret;
It forks twice, so there are 4 processes running. The screenshot shows the
beautiful output of process 4 (printing "d"s).
[ Path: | persistent link ] | |
| Filesystems: read and write via mmap? (22.05.2012) | |
Just a note to myself: While reading a blog posting about improved
file I/O performance via memory mapped files, I wondered whether
it might make sense to write an mmap() implementation first and then
create open, lseek, read and write
as functions which use an
mmap()ped file. Every read() or write() would just turn into a
memcpy(), an lseek() would just set an offset variable associated
with an mmap()ped file. Plus, the code for transfering disk
blocks to memory is likely to be similar to the code needed for
paging in a page that was written to disk.
There would be a problem with large files, obviously, because
a mapping cannot be larger than the address space.
[ Path: | persistent link ] | |
| Processes, little updates, serial console (20.05.2012) | |
I'm working on the process code. So far I can create the
initial process, run it (in usermode) and make it fork
(via a syscall). There's
also an initial implementation of a simple scheduler that
is supposed to switch between tasks 1 and 2 (which does not
work yet; after changing to the second process the system
crashes, because the stack is corrupt. I can fix the stack,
but then I get the same problem when switching back to
task 1. So there is some weird error in there).
Other new stuff in Ulix: I have a serial console (thanks to
the code from the
xv6
operating system, but I'm only using the functionality
of duplicating all terminal output in a terminal window
on the host (good for long memory dumps which scroll out of
the window). I've also added a "hlt" instruction in the
kgetch() function, so my notebook does not get hot any
longer :)
[ Path: | persistent link ] | |
| Bug fix :) (19.05.2012) | |
I found a bug in memory management that came into being after
including code for creating new address spaces: When there is
more than one address space, we have (identical) copies of
the page directory's mapping for c0000000..ffffffff -- so when
an entry in that area is modifed (i.e. a new page table is
created and linked from that page directory)
it must also be modified in
all existing copies... Took me quite a while to find it, but
now the code is OK :) Memory setup works for processes (as
long as no more than 4 MB are requested; can be fixed easily),
so the system is ready for process creation.
[ Path: | persistent link ]
| |
| Ulix has address spaces (05.04.2012) | |
Another step on the way to proper process management: Ulix now has address
spaces which can be switched on. So there is "process-private" memory
(however: no process yet).
To do: more work on address spaces (there are some bugs in there); integrate
address spaces + usermode switch + process table (not defined yet). For
starters, only cooperative scheduling.
[ Path: | persistent link ]
| |
| User mode stuff: side project (02.04.2012) | |
Since I'm giving the lecture "System Level Programming" at Nuernberg Univ. of Applied Sciences,
I use the practical coursework to develop some user mode tools for Ulix. Currently I'm working
on a simple shell. So far it can evaluate parameters and launch processes (assuming there are
working fork() and exec() functions).
fork() should not be a problem at all (once I have a process table), exec() can't be done properly
yet since there is no filesystem code at all. However, exec() could load a binary from RAM. I had
already experimented with precompiled programs stored in the Ulix code as byte arrays.
[ Path: | persistent link ]
| |
| Update: Development goes on, Moved to Erlangen (12.01.2012) | |
I've moved to Erlangen (where research and Ulix development are done), so
now I'm closer to the project, and things will continue faster this year.
Keep watching for new features :)
[ Path: | persistent link ]
| |
| User Mode (21.08.2011) | |
Ulix can now switch to user mode and execute simple code. Since we have no syscalls
yet, it cannot do much in user mode. So the next step is to set up syscalls
for "print character" and "read character" -- then I can convert the current
simple shell into a user mode shell. This is not yet a process, it is just code
being executed with privilege level 3 (in ring 3) instead of the kernel's own
privilege level 0 (ring 0). However, it's nice to have it, because the transition
from kernel to user mode requires weird code and a TSS (Task State Segment).
[ Path: | persistent link ]
| |
| Ulix has simple kmalloc() and kfree() functions (19.08.2011) | |
A first implementation of kmalloc and kfree is now available.
It always starts with a fresh page, so it is quite wasteful. Also, it does not
check, whether contiguous pages are allocated by request_new_page -- but
the code for that function has been prepared so that (in the future) it will
be able to guarantee a contiguous area.
The way new page tables are entered into the system has changed: I no longer
allocate pages for them, only frames. They do not need to have virtual
addresses because they are always referenced via their physical addresses.
[ Path: | persistent link ]
| |
| Remembering: there's a thing called scope (18.08.2011) | |
Back to "Learning C 101": Assume you create a new page table, and you do that
within a function. That page table is supposed to stay around (even
though it's never explicitly accessed outside the function, however it's
being pointed to.)
Sometimes the code works, sometimes not. You spend half a day on searching
for the errors in the paging calculations... Perhaps something's wrong with
the physical addresses? But not always? The code looks like this:
void create_new_table() {
page_table pt;
... (fill pt with data)
... (enter &pt in global page directory)
return;
}
Then, suddenly, at 4:00 a.m. in the morning, you realize that this way
return is an implicit forget about pt. D'oh.
In related news, moving the pt declaration outside the function solved
my problem, and now Ulix can reserve new pages (and correctly update the
page tables) until it runs out of physical frames :)
Yes, there's still the issue of paging out memory to disk. Which would
require disk access. Which is a topic for later.
[ Path: | persistent link ] | |
| v0.04: Memory Allocation: Get Frame, Get Page, Update Page Tables (17.08.2011) | |
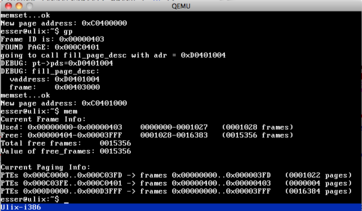 OK, the memory system is slowly becoming useful. There's now a bitmap that keeps
track of used/free frames in RAM, and there's a function which requests a new
page (first getting a frame, then updating the page table and eventually creating
a new page table when the old one is full). Next up is some kind of kmalloc()...
OK, the memory system is slowly becoming useful. There's now a bitmap that keeps
track of used/free frames in RAM, and there's a function which requests a new
page (first getting a frame, then updating the page table and eventually creating
a new page table when the old one is full). Next up is some kind of kmalloc()...
Some other things I found out: It's sometimes helpful to use the graphical
debug frontend of Bochs. And: There's a free (LGPL-licensed), simple printf() implementation
(Georges Menie, 2002) which does not depend on the existence of any libraries:
all it needs is a way to put a single character on the console (and I have a
putch() already).
Resources used:
printf, by Georges Menie, http://www.menie.org/georges/embedded/
[ Path: | persistent link ] | |
| Debugging the Kernel with Bochs (14.08.2011) | |
Debugging the Ulix kernel requires use of some tools: I use
Bochs (a fresh compile with the configure options
--enable-debugger and --enable-disasm).
Compared to a standard configuration of Bochs, I do a few
things differently via the config file (bochsrc.txt):
All of that together makes debugging the kernel a bit easier:
Bochs can show information about registers, the GDT, TSS and
many more interesting things.
Resources used:
Bochs, http://bochs.sourceforge.net/
[ Path: | persistent link ] | |
| Preparations for User Mode (13.08.2011) | |
In order to create user mode processes (without implementing a program
loader right now) I compile simple C programs (with a main() function)
to object files and link them with a ld linker script with
OUTPUT_FORMAT set to binary, creating a .com
file. (I use this ending in memory of simple DOS programs and because
yesterday the original IBM PC turned 30 years.)
Then comes some Unix
shell script magic which pipes the binary through hexdump, fmt, and sed
in order to create a char array declaration like this:
static char procbin[] __attribute__ ((aligned (4096))) = {
0x83, 0xec, 0x10, 0xc7, 0x44, 0x24, 0x0c, 0x00, 0x00, 0x00,
0x00, 0xc7, 0x44, 0x24, 0x08, 0x01, 0x00, 0x00, 0x00, 0xeb,
0x10, 0x8b, 0x44, 0x24, 0x08, 0x01, 0x44, 0x24, 0x0c, 0xff,
0x44, 0x24, 0x0c, 0xff, 0x44, 0x24, 0x08, 0x83, 0x7c, 0x24,
0x08, 0x09, 0x7e, 0xe9, 0xb8, 0xcd, 0xab, 0x00, 0x00, 0xcd,
0x80, 0x8b, 0x44, 0x24, 0x0c, 0x83, 0xc4, 0x10, 0xc3, 0x00
};
That can be pasted into the Ulix source code and will create a page-aligned
block holding the program. This is then mapped to page 0, and user mode is
entered with an IRET to address 0: The program starts.
In order to check what code has been produced by the compiler, I use
the disassembler udis86.
Resources used:
udis86 disassembler library with udcli client,
http://udis86.sourceforge.net/
[ Path: | persistent link ] | |
| Physical RAM mapped, hexdump (13.08.2011) | |
I've done some preparations for user mode: physical RAM (I assume 64 MByte RAM)
is now mapped to 0xD000.0000-0xD3FF.FFFF. That's helpful when I know the
physical address of some data, but not the virtual one. I noticed that it's
easy to forget that page directory entries need to point to physical
addresses, not virtual ones. I kept wondering why I got segfaults :)
There is now a "frame list" (actually just a bitmap). It can be asked for
the status of any frame (im RAM), and for each frame the status can be set
to free or used.
Another new function is hexdump() which displays (virtual) memory contents in
the same format as the shell command hexdump does for text files. It was fun
to compare its output with the output of 'hexdump ulix.bin'. My temporary
shell (the hard-coded main loop for now) cannot yet parse arguments to
commands, so hexdump will display contents of three memory areas selected in
the code; in a future version it will accept start and end addresses and
show the memory region's contents.
[ Path: | persistent link ]
| |
| v0.03: Paging with Higher Half Kernel (12.08.2011) | |
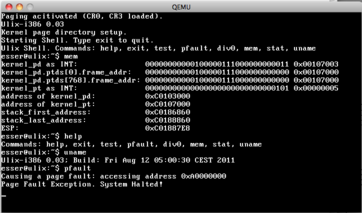 It works: now the kernel uses virtual addresses starting at 0xC0000000 (the last of four
gigabytes). This is a preparation for allowing user mode code (processes) to run in the
lower 3 GBytes. It took me all a whole day to get this to work because my original code
did not setup enough page -> frame mappings; it mapped some virtual memory to [0..1MB], but
the system was loaded to [1MB..2MB], so after enabling paging nothing useful was found...
It works: now the kernel uses virtual addresses starting at 0xC0000000 (the last of four
gigabytes). This is a preparation for allowing user mode code (processes) to run in the
lower 3 GBytes. It took me all a whole day to get this to work because my original code
did not setup enough page -> frame mappings; it mapped some virtual memory to [0..1MB], but
the system was loaded to [1MB..2MB], so after enabling paging nothing useful was found...
Now the next step will be user mode. For a starter I will just try to switch to user
mode and back; there's some meddling with the stack involved because Intel CPUs have
only one instruction that can be used to enter user mode: IRET (return from interrupt)
which finds the next instruction pointer on the stack. This will later turn into the
init process from which all other processes will be forked.
Another thing to think of now is memory allocation. When I start handling processes I will
need a list of free page frames, so the physical memory should be identified in the
beginning. There's a lot of untested frame allocation code in Felix Freiling's non-Intel Ulix,
so I'll look how that works on an Intel chip.
Resources used:
Higher Half With GDT, http://wiki.osdev.org/Higher_Half_With_GDT
[ Path: | persistent link ] | |
| Working on the GDT trick (11.08.2011) | |
In order to make the kernel use (virtual) high memory addresses (0xC000.0000 to 0xFFFF.FFFF),
some extra work is necessary. I am porting the GDT trick over to the current code which
uses a special GDT that linearly remaps memory by supplying a relocation offset as part
of a segment description.
Resources used:
Higher Half With GDT, http://wiki.osdev.org/Higher_Half_With_GDT
[ Path: | persistent link ] | |
| Ulix v0.01 - it begins (01.07.2011) | |
So here's the beginning of my ULIX blog, and also the beginning of my Ulix-i386
development. I base my work on Felix Freiling's "The Design and Implementation of
the ULIX Operating System", an unfinished literate programming document from which
parts of an OS theory book (in LaTeX) and parts of a kernel (in C and assembler)
can be extracted using the noweb tools (noweave, notangle).
The original code from this document is intended to run on a virtual machine
(the ULIX hardware) which is also described in that text and for which parts of
a tool chain (emulator, gcc port, assembler) had been created by other
students. However, I am implementing Ulix for the i386 architecture. So some
of the original code will remain, and some must go.
In this blog I will keep you updated on my progress.
[ Path: | persistent link ] | |
Copyright © 2011-2015 Hans-Georg Eßer;
Server: Debian Linux, Apache Web Server,
blog page powered by blosxom :: the zen of blogging,
Theme: Hazard Area 1.6 (modified),
created by Bryan Bell,
Copyright © 2000-2006 Weblogger.com.
|