ULIX: Literate Unix
ULIX: Literate Unix
A diary documenting the implementation of ULIX-i386
|
Welcome to the ULIX blog.
Ulix (Literate Unix) is a Unix-like operating system developed at
University of Erlangen-Nürnberg.
I use D. E. Knuth's concept of
Literate Programming
for the implementation and documentation. The goal was a fully working system which can be
used in operating system courses to show students how OS concepts (such as paging and scheduling)
can be implemented. Literate programs are very accessible because they can be read like a book;
the order of presentation is not enforced by program logic or compiler restrictions, but instead
is guided by the implementer's creative process.
Ulix is written in C and assembler for the Intel architecture. The literate programming
part is handled by noweb.
On this page I document my progress with the implementation.
|

|
Navigation:
2015 |
2014 |
2013 |
2012 |
2011
|
| User Mode (21.08.2011) | |
Ulix can now switch to user mode and execute simple code. Since we have no syscalls
yet, it cannot do much in user mode. So the next step is to set up syscalls
for "print character" and "read character" -- then I can convert the current
simple shell into a user mode shell. This is not yet a process, it is just code
being executed with privilege level 3 (in ring 3) instead of the kernel's own
privilege level 0 (ring 0). However, it's nice to have it, because the transition
from kernel to user mode requires weird code and a TSS (Task State Segment).
[ Path: | persistent link ]
| |
| Ulix has simple kmalloc() and kfree() functions (19.08.2011) | |
A first implementation of kmalloc and kfree is now available.
It always starts with a fresh page, so it is quite wasteful. Also, it does not
check, whether contiguous pages are allocated by request_new_page -- but
the code for that function has been prepared so that (in the future) it will
be able to guarantee a contiguous area.
The way new page tables are entered into the system has changed: I no longer
allocate pages for them, only frames. They do not need to have virtual
addresses because they are always referenced via their physical addresses.
[ Path: | persistent link ]
| |
| Remembering: there's a thing called scope (18.08.2011) | |
Back to "Learning C 101": Assume you create a new page table, and you do that
within a function. That page table is supposed to stay around (even
though it's never explicitly accessed outside the function, however it's
being pointed to.)
Sometimes the code works, sometimes not. You spend half a day on searching
for the errors in the paging calculations... Perhaps something's wrong with
the physical addresses? But not always? The code looks like this:
void create_new_table() {
page_table pt;
... (fill pt with data)
... (enter &pt in global page directory)
return;
}
Then, suddenly, at 4:00 a.m. in the morning, you realize that this way
return is an implicit forget about pt. D'oh.
In related news, moving the pt declaration outside the function solved
my problem, and now Ulix can reserve new pages (and correctly update the
page tables) until it runs out of physical frames :)
Yes, there's still the issue of paging out memory to disk. Which would
require disk access. Which is a topic for later.
[ Path: | persistent link ] | |
| v0.04: Memory Allocation: Get Frame, Get Page, Update Page Tables (17.08.2011) | |
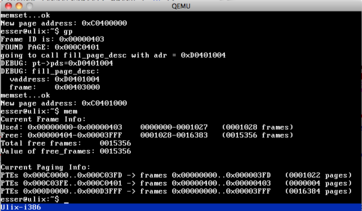 OK, the memory system is slowly becoming useful. There's now a bitmap that keeps
track of used/free frames in RAM, and there's a function which requests a new
page (first getting a frame, then updating the page table and eventually creating
a new page table when the old one is full). Next up is some kind of kmalloc()...
OK, the memory system is slowly becoming useful. There's now a bitmap that keeps
track of used/free frames in RAM, and there's a function which requests a new
page (first getting a frame, then updating the page table and eventually creating
a new page table when the old one is full). Next up is some kind of kmalloc()...
Some other things I found out: It's sometimes helpful to use the graphical
debug frontend of Bochs. And: There's a free (LGPL-licensed), simple printf() implementation
(Georges Menie, 2002) which does not depend on the existence of any libraries:
all it needs is a way to put a single character on the console (and I have a
putch() already).
Resources used:
printf, by Georges Menie, http://www.menie.org/georges/embedded/
[ Path: | persistent link ] | |
| Debugging the Kernel with Bochs (14.08.2011) | |
Debugging the Ulix kernel requires use of some tools: I use
Bochs (a fresh compile with the configure options
--enable-debugger and --enable-disasm).
Compared to a standard configuration of Bochs, I do a few
things differently via the config file (bochsrc.txt):
All of that together makes debugging the kernel a bit easier:
Bochs can show information about registers, the GDT, TSS and
many more interesting things.
Resources used:
Bochs, http://bochs.sourceforge.net/
[ Path: | persistent link ] | |
| Preparations for User Mode (13.08.2011) | |
In order to create user mode processes (without implementing a program
loader right now) I compile simple C programs (with a main() function)
to object files and link them with a ld linker script with
OUTPUT_FORMAT set to binary, creating a .com
file. (I use this ending in memory of simple DOS programs and because
yesterday the original IBM PC turned 30 years.)
Then comes some Unix
shell script magic which pipes the binary through hexdump, fmt, and sed
in order to create a char array declaration like this:
static char procbin[] __attribute__ ((aligned (4096))) = {
0x83, 0xec, 0x10, 0xc7, 0x44, 0x24, 0x0c, 0x00, 0x00, 0x00,
0x00, 0xc7, 0x44, 0x24, 0x08, 0x01, 0x00, 0x00, 0x00, 0xeb,
0x10, 0x8b, 0x44, 0x24, 0x08, 0x01, 0x44, 0x24, 0x0c, 0xff,
0x44, 0x24, 0x0c, 0xff, 0x44, 0x24, 0x08, 0x83, 0x7c, 0x24,
0x08, 0x09, 0x7e, 0xe9, 0xb8, 0xcd, 0xab, 0x00, 0x00, 0xcd,
0x80, 0x8b, 0x44, 0x24, 0x0c, 0x83, 0xc4, 0x10, 0xc3, 0x00
};
That can be pasted into the Ulix source code and will create a page-aligned
block holding the program. This is then mapped to page 0, and user mode is
entered with an IRET to address 0: The program starts.
In order to check what code has been produced by the compiler, I use
the disassembler udis86.
Resources used:
udis86 disassembler library with udcli client,
http://udis86.sourceforge.net/
[ Path: | persistent link ] | |
| Physical RAM mapped, hexdump (13.08.2011) | |
I've done some preparations for user mode: physical RAM (I assume 64 MByte RAM)
is now mapped to 0xD000.0000-0xD3FF.FFFF. That's helpful when I know the
physical address of some data, but not the virtual one. I noticed that it's
easy to forget that page directory entries need to point to physical
addresses, not virtual ones. I kept wondering why I got segfaults :)
There is now a "frame list" (actually just a bitmap). It can be asked for
the status of any frame (im RAM), and for each frame the status can be set
to free or used.
Another new function is hexdump() which displays (virtual) memory contents in
the same format as the shell command hexdump does for text files. It was fun
to compare its output with the output of 'hexdump ulix.bin'. My temporary
shell (the hard-coded main loop for now) cannot yet parse arguments to
commands, so hexdump will display contents of three memory areas selected in
the code; in a future version it will accept start and end addresses and
show the memory region's contents.
[ Path: | persistent link ]
| |
| v0.03: Paging with Higher Half Kernel (12.08.2011) | |
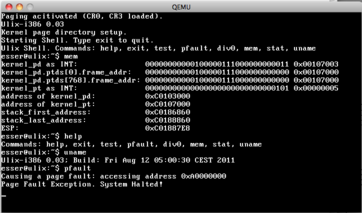 It works: now the kernel uses virtual addresses starting at 0xC0000000 (the last of four
gigabytes). This is a preparation for allowing user mode code (processes) to run in the
lower 3 GBytes. It took me all a whole day to get this to work because my original code
did not setup enough page -> frame mappings; it mapped some virtual memory to [0..1MB], but
the system was loaded to [1MB..2MB], so after enabling paging nothing useful was found...
It works: now the kernel uses virtual addresses starting at 0xC0000000 (the last of four
gigabytes). This is a preparation for allowing user mode code (processes) to run in the
lower 3 GBytes. It took me all a whole day to get this to work because my original code
did not setup enough page -> frame mappings; it mapped some virtual memory to [0..1MB], but
the system was loaded to [1MB..2MB], so after enabling paging nothing useful was found...
Now the next step will be user mode. For a starter I will just try to switch to user
mode and back; there's some meddling with the stack involved because Intel CPUs have
only one instruction that can be used to enter user mode: IRET (return from interrupt)
which finds the next instruction pointer on the stack. This will later turn into the
init process from which all other processes will be forked.
Another thing to think of now is memory allocation. When I start handling processes I will
need a list of free page frames, so the physical memory should be identified in the
beginning. There's a lot of untested frame allocation code in Felix Freiling's non-Intel Ulix,
so I'll look how that works on an Intel chip.
Resources used:
Higher Half With GDT, http://wiki.osdev.org/Higher_Half_With_GDT
[ Path: | persistent link ] | |
| Working on the GDT trick (11.08.2011) | |
In order to make the kernel use (virtual) high memory addresses (0xC000.0000 to 0xFFFF.FFFF),
some extra work is necessary. I am porting the GDT trick over to the current code which
uses a special GDT that linearly remaps memory by supplying a relocation offset as part
of a segment description.
Resources used:
Higher Half With GDT, http://wiki.osdev.org/Higher_Half_With_GDT
[ Path: | persistent link ] | |
| Ulix v0.01 - it begins (01.07.2011) | |
So here's the beginning of my ULIX blog, and also the beginning of my Ulix-i386
development. I base my work on Felix Freiling's "The Design and Implementation of
the ULIX Operating System", an unfinished literate programming document from which
parts of an OS theory book (in LaTeX) and parts of a kernel (in C and assembler)
can be extracted using the noweb tools (noweave, notangle).
The original code from this document is intended to run on a virtual machine
(the ULIX hardware) which is also described in that text and for which parts of
a tool chain (emulator, gcc port, assembler) had been created by other
students. However, I am implementing Ulix for the i386 architecture. So some
of the original code will remain, and some must go.
In this blog I will keep you updated on my progress.
[ Path: | persistent link ] | |
Copyright © 2011-2015 Hans-Georg Eßer;
Server: Debian Linux, Apache Web Server,
blog page powered by blosxom :: the zen of blogging,
Theme: Hazard Area 1.6 (modified),
created by Bryan Bell,
Copyright © 2000-2006 Weblogger.com.
|